When Should You Use RAG in Your SaaS — And When It’s a Waste of Time
⚡ TL;DR
- RAG is powerful, but not every SaaS needs it
- Use RAG when your product depends on dynamic, domain-specific data
- Avoid RAG in early MVPs or simple CRUD apps
- Biggest mistake: focusing on models instead of data quality and retrieval
- RAG is a business decision, not just a technical one
The Real Scenario Every Founder Is Facing
“We want to add AI to our product.”
That’s the brief.
Not:
- What problem AI solves
- What data it uses
- Whether it’s even needed
Just… “add AI.”
This is where most SaaS products start going wrong.
⚠️ The Core Problem with LLMs in SaaS
Out of the box, models like OpenAI’s GPT:
- Don’t know your internal data
- Can hallucinate confidently
- Can’t stay updated with real-time business context
So founders face a choice:
- Fine-tune a model
- Or use RAG (Retrieval-Augmented Generation)
Most pick RAG… without understanding if they should.
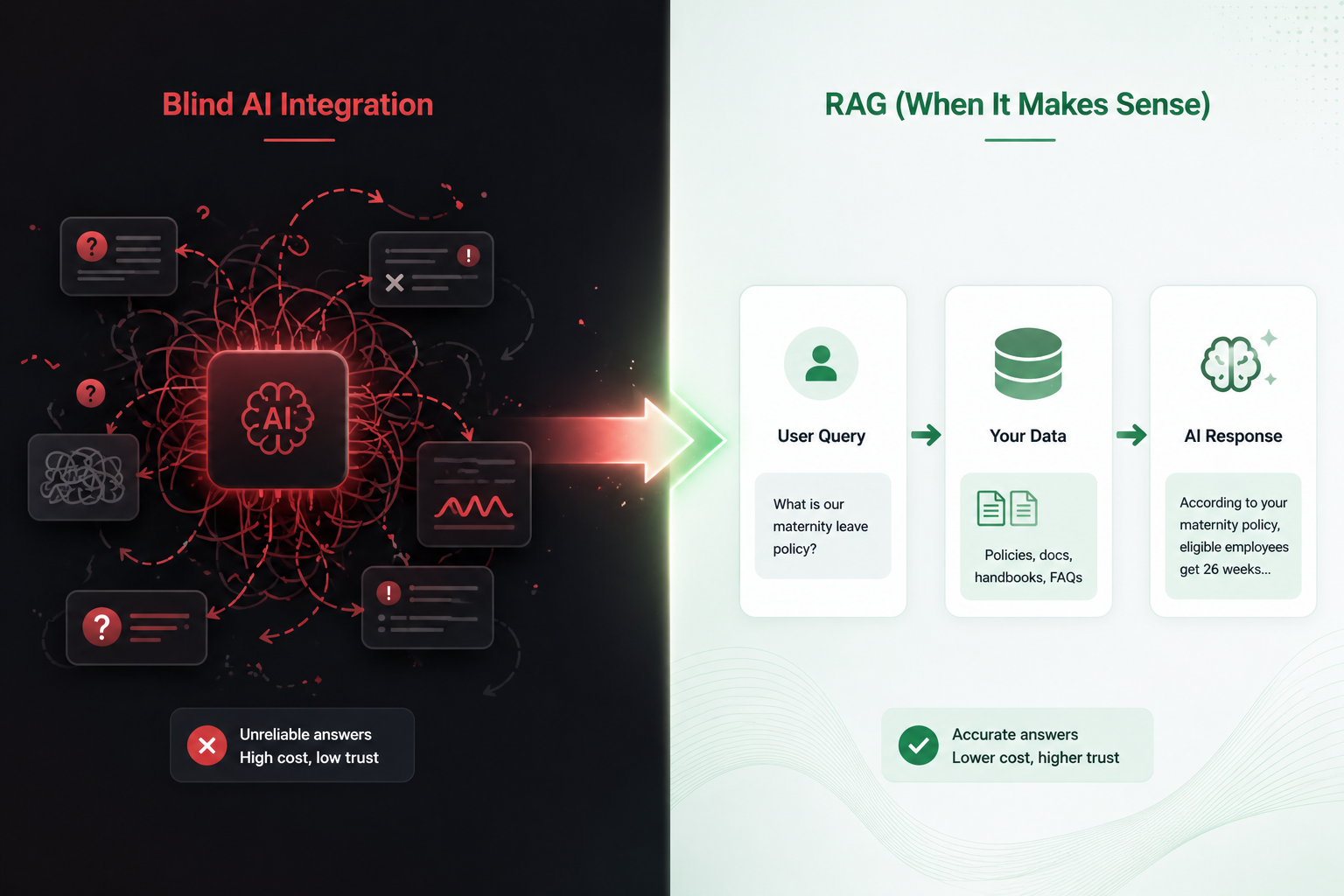
🧩 What RAG Actually Does (Simple View)
At a high level:
- User asks a question
- System searches your data (via embeddings)
- Relevant context is retrieved
- LLM generates an answer using that context
Think of it as:
“LLM + your private knowledge layer”
✅ When RAG Makes Sense (High ROI Use Cases)
1. Knowledge-Heavy Products
- HRM systems
- Legal/compliance platforms
- Internal company tools
If your product depends on documents, policies, or structured knowledge, RAG fits naturally.
2. Customer Support Automation
- Chatbots trained on help docs
- Ticket deflection systems
- Context-aware support assistants
RAG ensures answers come from your actual documentation, not generic AI guesses.
3. Multi-Tenant SaaS with User Data
- Each customer has their own dataset
- AI responses must be context-specific
RAG allows scoped retrieval per tenant.
4. Frequently Changing Data
Fine-tuning fails here.
RAG wins because:
- You update data → system reflects instantly
- No retraining cycles
❌ When RAG is a Waste of Time
1. Early MVP with No Real Users
If you don’t even know:
- What users ask
- What data matters
RAG is premature optimization.
2. Simple CRUD SaaS
Dashboards, forms, basic workflows:
You don’t need:
- Vector DB
- Embeddings pipeline
- Retrieval layer
This is engineering theater, not value.
3. “AI for Marketing” Features
If your use case is:
- “Generate a tagline”
- “Write a description”
Use a plain API call.
RAG adds complexity with zero ROI.
4. Poor or Unstructured Data
This is critical.
If your data is:
- Messy
- Redundant
- Unstructured
RAG will fail silently.
Garbage in → confident garbage out
⚡ What Actually Matters (Founders Miss This)
1. Data Quality > Model Choice
Everyone debates GPT vs open-source.
Reality:
- Clean, structured data beats model upgrades
2. Retrieval Quality is the Core System
Bad retrieval = irrelevant context = bad answers
Your stack is only as good as:
- Chunking strategy
- Embedding quality
- Search relevance
3. Latency and Cost Scale Fast
RAG adds:
- Embedding costs
- Vector DB queries
- Longer response pipelines
At scale, this becomes a real line item.
🏗️ Practical Tech Stack (Lean + Scalable)
Keep it simple:
- Backend: Node.js / Laravel
- Queue: Redis + BullMQ
- Vector DB: Pinecone / pgvector
- LLM: OpenAI APIs
- Storage: S3 / database
Avoid overengineering early.
🧠 The Strategic Insight Most Founders Miss
RAG is not an “AI feature.”
It’s a data access strategy.
If your product doesn’t rely on:
- contextual knowledge
- dynamic data retrieval
Then RAG is solving a problem you don’t have.
🔥 Final Thought
Before adding RAG, ask:
“What specific user question requires our internal data to answer correctly?”
If you can’t answer that clearly:
You don’t need RAG yet.
